


















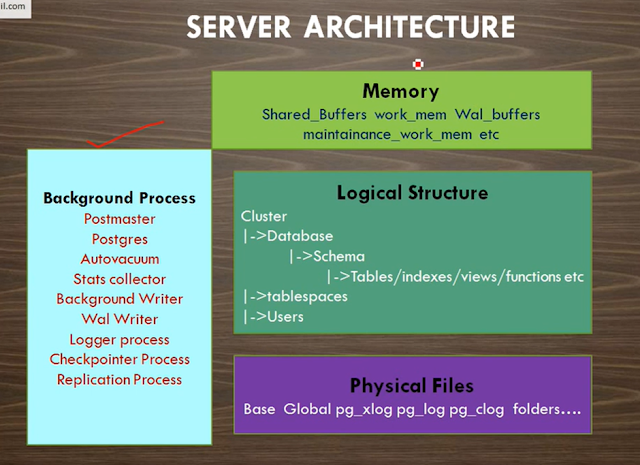
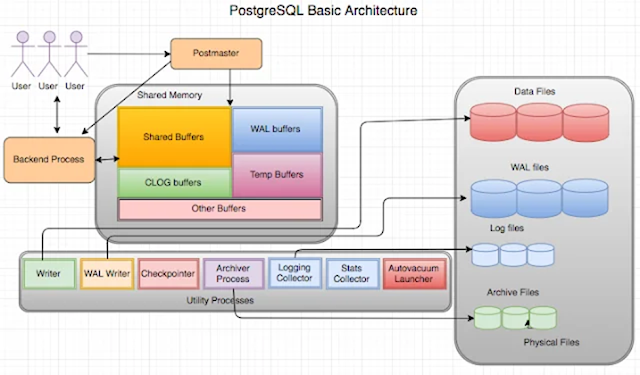
Postmaster
Process: Postmaster is the first process which gets starts when
the Postgres cluster starts. The postmaster process acts as a supervisor. Postmaster act as
a listener at
a server-side,
any new connection coming in, it will first connect to the postmaster and every
time for every connection postmaster creates “postgres” process. Postmaster runs on the default
port number 5432 and
we can change or reconfigure port
no. There is one postmaster for one cluster. Postmaster process is
a parent of
all in a PostgreSQL Server. If
you check the relationships between processes with the pstree command, you can
see that the Postmaster
process is the parent
process of all processes. In the below output, if you
notice PID: 88808 (Postmaster process) is a parent
of all backend & background processes.
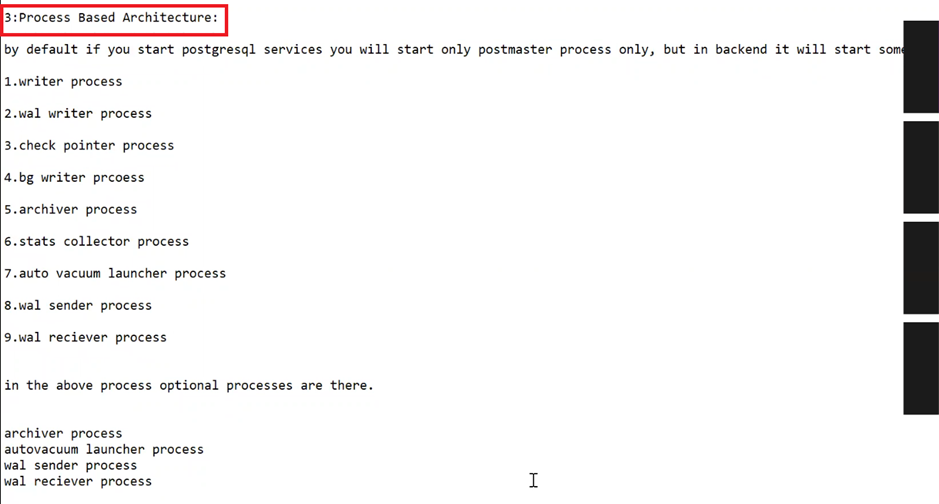
2. Background (Utility) Process
The list of background processes required
for PostgreSQL operation
is as follows.
Logger Process: Writes into
the logs file. Basically, all the error logs are recorded by this and written
into the log files.
Checkpointer Process
: During the checkpoint, the cache content on the
shared memory is written to the database file, so that the state of the memory
and the file are consistent. In this way, you can shorten the recovery time
from WAL when the system crashes, and also prevent the infinite growth of WAL.
The checkpoint_segments and checkpoint_timeout of postgresql.conf can
be used to specify the time interval for performing checkpoints. the checkpoint
will occur in the following scenarios: pg_start_backup, create a database, pg_ctl stop|restart, pg_stop_backup, and
few others.
Writer process: The Writer
process writes the cache on the shared memory to the disk at the appropriate
time. Through this process, you can prevent the performance of a large number
of writes to disk during checkpoint (checkpoint)
from deteriorating, so that the server can maintain relatively stable
performance. The Background writer has been resident in memory since it got up,
but it has not been working. It will sleep after a period of work. The sleep
interval is set by the parameter bgwriter_delay in
postgresql.conf. The default is 200
microseconds.
WAL Writer: The WAL writer process
writes the WAL cache on
the shared memory to
the disk at
an appropriate point in time. This way, you can reduce the pressure on the
back-end process when writing its own WAL cache and improve
performance. The core idea of the write-ahead log is
that the modification of the data file must only occur after these
modifications have been recorded in the log, that is, the log is written first and
then the data is written (log first). Using this mechanism can avoid frequent
data writing to the disk and can reduce disk I/O. The database can use these
WAL logs to recover the database after a downtime restart.
Autovacuum Launcher: The
autovacuum-worker processes are invoked for the vacuum process periodically (it
request to create the autovacuum workers to the Postgres server).
Archive Process: Archive process
transfers WAL logs to
the archive location.
The archiver process is an optional process, default is OFF. Setting up the
database in Archive
mode means capturing the WAL data of each segment file
once it is filled and save that data somewhere before the segment file is
recycled for reuse. The purpose of the archive log is for the database to use
the full backup and the archive log generated after the backup so that the
database returns to any point in the past (PITR).
Stats
Collector: DBMS usage
statistics such as session execution information ( pg_stat_activity ) and
table usage statistical information ( pg_stat_all_tables ) are collected. The
statistics collector transmits the collected information to other PostgreSQL
processes through temporary files. These files are stored in the directory
named by the stats_temp_directory parameter, pg_stat_tmp by default.
3. Backend Process
The maximum number of backend processes is
set by the max_connections parameter, and the default
value is 100. The backend process performs the query request of the user
process and then transmits the result. Some memory structures are required for
query execution, which is called local memory. The main parameters
associated with local memory are:
- work_mem Space
used for sorting, bitmap operations, hash joins, and merge joins. The
default setting is 4 MB.
- Maintenance_work_mem Space used for Vacuum and CREATE INDEX. The default setting
is 64 MB.
- Temp_buffers Space
used for temporary tables. The default setting is 8 MB.
4. Client Process
Client Process refers to the
background process that is assigned for every backend user connection. Usually,
the postmaster process will fork a child process that is dedicated to serving a
user connection.

Postmaster which is first process which is started when your
cluster is started, this postmaster process will be listening what on different
port number so it is like
When client connection comes to the postmaster process , he
will spawn a new process once your connection authorized and authenticated he
will spawn a new process for called a postgresql process.
For every client process there will be a new progres process
spawn and the client connection will directly interact with new postgres process from then onwards.

1)
shared_buffers (integer)
The shared_buffers parameter
determines how much memory
is dedicated to the server for caching data.
The default value for
this parameter, which is set in postgresql.conf, is:
#shared_buffers = 128MB
The value should be
set to 15% to 25% of the machine’s total RAM. For example: if your machine’s
RAM size is 32 GB, then the recommended value for shared_buffers is 8
GB. Please note that the database server needs to be restarted after this
change.
2)
work_mem (integer)
The work_mem parameter basically provides
the amount of memory to be
used by internal sort operations and hash tables before writing to temporary disk
files. Sort operations are used for order by, distinct, and merge join
operations. Hash tables are used in hash joins and hash based aggregation.
The default value for this parameter, which is set
in postgresql.conf, is:
#work_mem = 4MB Setting the correct value of work_mem parameter can
result in less disk-swapping, and therefore far quicker queries.
We can use the formula below to calculate the optimal work_mem value for the database
server:
Work_Mem= Total RAM * 0.25 / max_connectionsThe max_connections parameter is
one of the GUC parameters to specify the maximum number of
concurrent connections to the database server. By default it is set to 100
connections
maintenance_work_mem (integer)
The maintenance_work_mem parameter
basically provides the maximum amount of memory to be used by maintenance
operations like vacuum, create index, and alter table add
foreign key operations.
The default value for
this parameter, which is set in postgresql.conf, is:
#maintenance_work_mem = 64MB
It’s recommended to
set this value higher than work_mem; this can improve performance for
vacuuming. In general it should be:
Total RAM * 0.05
effective_cache_size
(integer)
The effective_cache_size parameter estimates how much memory is
available for disk caching by the operating system and within the database
itself. The PostgreSQL query planner decides whether it’s fixed in RAM or not.
Index scans are most likely to be used against higher values; otherwise,
sequential scans will be used if the value is low. Recommendations are to
set Effective_cache_size at 50% of the machine’s total RAM.
For more details and other parameters, please refer to the
PostgreSQL documentation:
PostgreSQL
Architecture – Memory Components
In this post we will
discuss Memory Components of PostgreSQL, Memory
Components in PostgreSQL can
be divided mainly into two category memory region 1). Shared Memory 2). Process Memory or Backend Memory
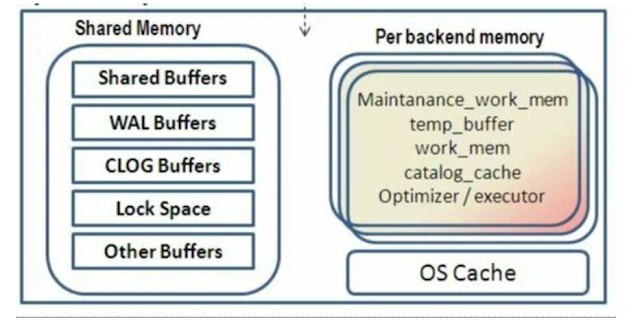
Shared Memory
Shared Memory: Shared
Memory refers to the memory reserved for database caching and transaction log
caching. This area is used
by all processes of a PostgreSQL server. When the server
gets started, it occupies some of the memory from the RAM. Depending upon the
various parameters like shared_buffers, wal_buffers,
etc.
Shared Memory can be further classified as follow:
Shared Buffer: Sets the amount
of memory the database server uses for shared memory buffers. The purpose of
Shared Buffer is to minimize
DISK IO. The shared buffers are accessed by all the background
servers and user processes connecting to the database. The data that is written
or modified in this location is called “dirty data” and the unit of operation
being database blocks (or pages), the modified blocks are also called “dirty
blocks” or “dirty pages”. Shared buffers are controlled by the parameter shared_buffers.
WAL (Write Ahead Log)
Buffer: The WAL buffer is a buffer
that temporarily
stores changes to the database. This WAL data is the
metadata information about changes to the actual data and is sufficient to
reconstruct actual data during database recovery operations. The WAL data is
written to a set of physical files in a persistent location called “WAL segments“. The WAL
buffer’s memory allocation is controlled by the wal_buffers parameter.
Clog Buffer: CLOG stands
for “commit log”
CLOG buffers is an area to hold commit
log pages. The commit log pages contain a log of transaction metadata and
differ from the WAL data. The commit logs have the commit status of all
transactions and indicate whether or not a transaction has been completed
(committed). There is no
specific parameter to control this area of memory. This is
automatically managed by the database engine in tiny amounts.
Lock Space (Memory for
Locks): This memory component is to store all heavyweight locks used
by the PostgreSQL instance. These locks are shared across all the background
servers and user processes connecting to the database. A setting of two
database parameters namely max_locks_per_transaction and max_pred_locks_per_transaction in
way influences the size of this memory component.
Process Memory or Backend Memory
Process Memory: This
memory area is allocated
by each backend process for its own use. It is temporarily used
privately by each Postgres process. By default, each session will take size of
4Mb. Eg.: If there are 100 sessions, then they will consume 400 Mb.
Process Memory can be further classified as follow:
Vacuum Buffers: This is the
maximum amount of memory used by each of the autovacuum worker processes, and
it is controlled by the autovacuum_work_mem database
parameter. The memory is allocated from the operating system RAM and is also influenced
by the autovacuum_max_workers database
parameter. All these parameter settings only come into play when the auto vacuum daemon is enabled.
This memory component is not shared by any other background server or user
process.
Work Memory: This is the
amount of memory reserved for either a single sort or hash table operation
in a query and it is controlled by work_mem parameter.
A sort operation could be one of an ORDER
BY, DISTINCT, or Merge join and
a hash table operation
could be due to a hash-join, hash-based aggregation, or
an IN subquery.
A single complex query may have any numbers of such sort or hash table operations,
and as many chunks of
memory allocations defined by the work_mem parameter
will be created for each of those operations in a user connection.
Maintenance Work Memory: This is the
maximum amount of memory allocation of RAM consumed for maintenance operations.
A maintenance operation could be one of the VACUUM, CREATE INDEX, or
adding a FOREIGN KEY to
a table. The setting is controlled by the maintenance_work_mem database
parameter.
Temp Buffers: A database
may have one or more temporary tables, and the data blocks (pages) of
such temporary tables need a separate allocation of memory to be processed. The
temp buffers defined by the temp_buffers parameter.
The temp buffers are only used for access to temporary tables in a user
session.
postgres=# select name,setting,unit
from pg_settings where name like '%buffer%';
name
| setting | unit
----------------+---------+------
shared_buffers | 16384 | 8kB
temp_buffers
| 1024 | 8kB
wal_buffers
| 512 | 8kB
(3 rows)
postgres=#
postgres=#
postgres=# select name,setting,unit
from pg_settings where name like '%work_mem%';
name | setting | unit
----------------------+---------+------
autovacuum_work_mem | -1
| kB
maintenance_work_mem | 65536 | kB
work_mem | 4096 | kB
(3 rows)
Postgresql
Architecture – Physical Storage Structure
In this blog, we will discuss PostgreSQL architecture of
physical storage which can be categorized in below four part:
1. Data Directory
2. Physical Files
3. Data file layout (OID)
4. Database Structure

Specifies the directory to use for data storage. This parameter
can only be set at server start.
config_file: Specifies the main server configuration file called postgresql.conf. This
parameter can only be set on the Postgres command line.
hba_file: Specifies the configuration file for host-based authentication
called pg_hba.conf.
This parameter can only be set at the server start.
ident_file: Specifies the configuration file for user name mapping
called pg_ident.conf.
This parameter can only be set at the server start.
postmaster.opts file: A file recording the command-line options the
postmaster was last started with
postmaster.pid file: A lock file recording the
current postmaster PID and shared memory segment ID (not present after
postmaster shutdown)
PG_VERSION file : A file containing the major version number of PostgreSQL.
pg_wal directory: Here the write-ahead logs are stored. It is the
log file, where all the logs are stored of committed and uncommitted
transactions. It contains a maximum of 6 logs, and the last one overwrites. If
the archiver is
on, it moves there.
base directory: Subdirectory
containing per-database subdirectories.
global directory: Subdirectory containing cluster-wide tables,
such as pg_database.
pg_multixact directory: Subdirectory containing multi
transaction status data (used for shared row locks).
pg_subtrans directory: Subdirectory containing subtransaction
status data.
pg_tblspc directory: Subdirectory containing symbolic links to
tablespaces.
pg_twophase directory: Subdirectory containing state files
for prepared transactions.

Data Files: It
contains all the data required by the user for processing. Data from data files
are first moved to shared buffers and then the data is processed accordingly.
WAL Files/Segments: WAL
Buffers are linked with WAL Files/Segments. WAL buffer flushes all the data
into WAL Segment whenever commit command occurs. Commit is a command which
ensures the end of the transaction. Commit work by default after every command
in PostgreSQL which can also be changed accordingly.
Archived WAL/Files: This file
segment is a kind of copy of WAL Segment which stores all the archived data of
WAL Segment which can be stored for a long period. WAL segment is having
limited storage capacity. Once space is exhausted in WAL Segment, the system
starts replacing the old data with new data which results in the loss of old
data. Archives are required till full backup of the database. After that,
we can even delete the archive in order to gain some space in the DB.
Error Log Files: Those files
which contain all the error messages, warning messages, informational messages,
or messages belonging to all the major thing happening to the database. All
logs related to DDL and DML changes are not stored in this space. Internal
errors, internal bugs entry is stored in this file which helps the admin to
troubleshoot the problem.
3.
Data file layout (OID)
All database objects in postgreSQL are
managed internally by their respective object identifiers (OIDs), which are assigned
4 byte integers. The OID of
the database is stored in the pg_database system
table. The OIDs of objects such as tables, indexes, and sequences in the
database are stored in the pg_class system
table:
In the below example, we derived OID
of database, Tablespace & Table and we can
relate all OIDs with
function pg_relation_filepath, This
will give you the exact location where table datafiles located.
4.
Database Structure
Here are some things that are important to know
when attempting to understand the database structure of PostgreSQL.
Items related to the database
- PostgreSQL consists of several databases. This
is called a database cluster.
- When initdb () is
executed, template0 , template1 ,
and postgres databases are created.
- The template0 and template1 databases
are template databases for user database creation and contain the system
catalog tables.
- The list of tables in the template0 and template1 databases
is the same immediately after initdb (). However, the template1 database
can create objects that the user needs.
- The user database is created by cloning
the template1 database.
Items related to the tablespace
- The pg_default and pg_global tablespaces
are created immediately after initdb().
- If you do not specify a tablespace at the time
of table creation, it is stored in the pg_dafault tablespace.
- Tables managed at the database cluster level
are stored in the pg_global tablespace.
- The physical location of the pg_default tablespace
is $PGDATA\base.
- The physical location of the pg_global tablespace
is $PGDATA\global.
- One tablespace can be used by
multiple databases. At this time, a database-specific subdirectory is
created in the tablespace directory.
- Creating a user tablespace creates a symbolic
link to the user tablespace in the $PGDATA\tblspc directory.
Items related to the table
- There are three files per table.
- One is a file for storing table data. The file
name is the OID of the table.
- One is a file to manage table-free space. The
file name is OID_fsm.
- One is a file for managing the visibility of
the table block. The file name is OID_vm.
- The index does not have a _vm file.
That is, OID and OID_fsm are composed of
two files.





WAL file (redo log file in Oracle) = WAL writer ( LGWR-In Oracle)


























House keeping for logs:-
Normally client manager will ask to maintain log files for 3
months, in the months first 5 days in plain format, remaining 85 days in zip
format for that we have to create custom script to zip the log file older than
5 days. Log will be useful for audit purpose.


No comments:
Post a Comment